In academic chemistry, authors submit a promotional table-of-contents (ToC) image when publishing research papers in most journals. These fascinate me as they are one of the few places where unfettered self expression is tolerated, if not condoned. (See e.g. TOC ROFL, of which I am a multiple inductee)
{kind=link}
In general, though, ToC images follow a fairly consistent visual language, with distinct conventions followed in different subfields. This presents an vaguely plausible excuse to train some machine learning models to generate ToCs and their accompanying paraphenalia. In this project, I use ToC images, titles and abstracts from one of the most longest running and well-known chemistry journals, the Journal of the American Chemical Society (JACS) as a dataset to train:
- A generative adversarial network (StyleGAN3) - a model which learns to generate images similar to those in its training set.
- A finetuned version of GPT-2 that generates chemistry-paper-title-like lists of words.
- A vision encoder-decoder model (test it out here) that converts images to the appropriate text - here, the above GPT-2 model acts as the text generator.
- A T5 sequence-to-sequence model (test it out here) that generates a text sequence from a prompt.
For those who are interested in the inner workings or may want to do something similar, I’ve included a writeup of the project below. Examples of the code are available on my GitHub. As you’ll see, a lot of my choices were fairly abitrary, arising more-or-less from the availability heuristic.
Training the GAN
Getting the dataset ready
My initial idea was simply to see how well a GAN could generate ToC images, and so I needed a whole bunch of ToC images. I used the popular python package beautifulsoup with a headless browser and some simple loops to scrape the JACS website for the ToC images, titles and abstracts. The full dataset from around 60,000 papers could be collected overnight. Note: this was relatively easy with JACS (and ACS journals in general) as the website organisation follows a logical structure. YMMV for other publishers’ platforms.
Generally, ML training inputs for image models should be the same size, often with powers of 2 as values - StyleGAN3 uses square images of size 128, 256, 512, and 1024 pixels. Luckily, JACS ToC images are fixed to 500 pixels in width and maximum height. I padded the figures to 512x512 using Irfanview’s batch processing tool, then resized those images to generate smaller datasets at 128 and 256 px as well.
Running StyleGAN3
I chose StyleGAN3 as I had heard of it before and 3 was the latest version number. At the time of writing it appears to be one of the best & most mature GANs for image generation. The implementation is fairly user-friendly and includes various data preparation and training scripts; the documentation is excellent and deserves commendation.
The first step was to use the dataset_tool.py script to prepare a dataset in a form the model could use - something like this:
| |
After this, it’s straightforward to train the model using the following script:
| |
The key parameters that need to be set are batch size and gamma, which is the R1 regularization parameter. ‘cbase=16384’ speeds up training by sacrificing network capacity, but at low resolutions I didn’t find it to be a problem. Having only a humble RTX 3060 Ti (the best I could get during the GPU apocalypse of 2020-2021), the meagre 8 GB of VRAM was a limiting factor for batch sizes. I also found useful the –resume flag, which allows you to resume training from a previous network snapshot in case of crashes, although I found I also had to edit the resume_kimgs variable in the training script directly to get it to work properly. The tensorbard output is also very good, and can be run like so:
| |
I considered training on cloud compute but seemed to be more expensive than training locally, and also required learning a new thing. In retrospect this might have been a poor life choice. My wife was still annoyed that our power bill doubled during the month I was training though! Also that the computer was essentially a fan heater running in the bedroom during the height of summer. After bluescreening a couple of times I removed the computer side panel which dropped temps by a couple of degrees.
Fakes generated from a model trained on 128 px images
After training continuously for a few weeks, the 256 px model started to converge. In this case I used a common evaluation metric for GANs called the Fréchet Inception Distance (FID), a measure of similarity between image distributions. Below is a video of images generated from the model as it trains - each successive frame, the models has trained on an additional 40,000 images. Overall, the model saw images from the training set around 5 million times.
Generating fake ToC images
With the GAN model trained, it was time to generate the fake ToC images. This is done very simply with this StyleGAN script:
| |
The key parameters here are ψ (“trunc”), which controls the tradeoff between image quality and weirdness (higher values are weirder). Some examples below:
ψ = 0.2
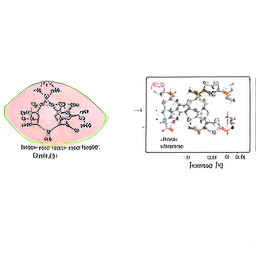
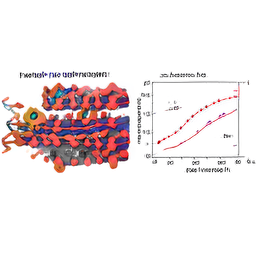
ψ = 0.8
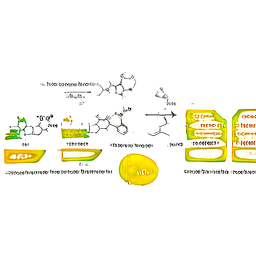
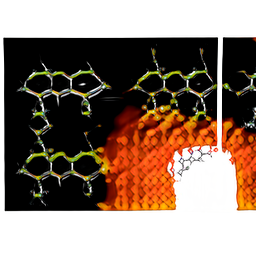
ψ = 1.1
Assembling a ToC to title model
With generated ToC images in hand, I wondered if it was possible to generate relevant paper titles. Having labels in the form of titles for all the ToCs in the training set, the challenge was finding an appropriate model. After trying a couple of things, I settled on using 🤗 Hugging Face’s transformers library, mostly due to its good documentation and straightforward code structuring.
I used the 🤗 vision encoder decoder model as the basis for the toc-to-title model. This model can easily be warm-started with a pretrained vision transformer plus a pretrained language transformer model. This is very convenient as big tech companies have already spent millions of dollars and vast amounts of compute training models which then can be easily fine-tuned or even just used out-of-the-box.
Fine-tuning GPT-2 to generate paper titles
I chose GPT-2 as the base for the language model. Once considered too dangerous to fully release, GPT-2 is now the most popular model hosted on Hugging Face. Much more powerful (and presumably commensurately dangerous) models such as the 20 billion parameter GPT-NeoX are now available (cf. the mere 1.5B parameters of GPT-2), however for the purposes of this project the relative computational tractability of tuning GPT-2 makes it an excellent choice.
GPT-2 is based on what is known as a decoder-only model (at this point, what I’ll dubb “Godwin’s law but for AI” comes into effect - as the length of this ML article increases, the probability that I’ll direct you to the original transformers paper, “Attention Is All You Need” , approaches 1). These models are good for text generation, but the base model is designed to generate text of an arbitrary length, so I had to make a couple of tweaks to get the model to generate paper-title-style sentences.
Language models such a GPT-2 first tokenize their inputs - that is, they break human-readable language into a set of tokens that may have some relationship to the underlying structure of the language, such as words, subwords, or in the case of GPT-2 byte-pair encoding. Additionally, tokens for special occurences such as beginning/end of sequence, or padding, can be used. As GPT-2 only uses end-of-sequence tokens by default, I added a padding token “<|pad|>” to distinguish between the padding required for setting all training inputs to the same size, and the actual end of a title. As a rank amateur, this took quite a long time to work out so I share it here in the hope that it may be helpful to someone. I may do a full writeup in a separate post. Sample code below:
| |
I then appended end-of-sequence tokens to each of the training outputs. Finally, it’s imporant to resize the token embeddings of the model so that the extra token is accounted for:
| |
Having done that, the model can then be trained and produces convincing results. Here’s a sample of real titles compared to GPT-2-JACS completions using the first 4 words of the real title as a prompt:
| Real | GPT-2-JACS completion |
|---|---|
| Origin of Dark-Channel X-ray Fluorescence from Transition-Metal Ions in Water | Origin of Dark-Channel X-ray Absorption Fine Structure of (NH3)4Ca(OH)5 in Supercritical Carbon Dioxide |
| Comprehensive Thermochemistry of W–H Bonding in the Metal Hydrides CpW(CO)2(IMes)H, \[CpW(CO)2(IMes)H\]•+, and \[CpW(CO)2(IMes)(H)2\]+. Influence of an N-Heterocyclic Carbene Ligand on Metal Hydride Bond Energies | Comprehensive Thermochemistry of W–H and H–H Bonds in the Lanthanide Phosphate (Ln5Me4) System |
| Fragmentation Energetics of Clusters Relevant to Atmospheric New Particle Formation | Fragmentation Energetics of Clusters Based on Cluster Modification: Assignment of the Concentration-Dependent Rate Constant |
| Transient Photoconductivity of Acceptor-Substituted Poly(3-butylthiophene) | Transient Photoconductivity of Acceptor-Substituted Layered Zirconium Oxides |
| Palladium-Catalyzed Aerobic Oxidative Cyclization of N-Aryl Imines: Indole Synthesis from Anilines and Ketones | Palladium-Catalyzed Aerobic Oxidative Cyclization of Unactivated Alkenes |
| Mild Aerobic Oxidative Palladium (II) Catalyzed C−H Bond Functionalization: Regioselective and Switchable C−H Alkenylation and Annulation of Pyrroles | Mild Aerobic Oxidative Palladium(II)-Catalyzed Arylation of Indoles: Access to Chiral Olefins |
| A Pentacoordinate Boron-Containing π-Electron System with Cl–B–Cl Three-Center Four-Electron Bonds | A Pentacoordinate Boron-Containing π-Electron System for High-Performance Polymer Solar Cells |
| Ferroelectric Alkylamide-Substituted Helicene Derivative with Two-Dimensional Hydrogen-Bonding Lamellar Phase | Ferroelectric Alkylamide-Substituted Helicene Derivative: Synthesis, Characterization, and Redox Properties |
| Tandem Cyclopropanation/Ring-Closing Metathesis of Dienynes | Tandem Cyclopropanation/Ring-Closing Metathesis of Cyclohexadienes: Convergent Access to Optically Active α-Hydroxy Esters |
| Cyclic Penta-Twinned Rhodium Nanobranches as Superior Catalysts for Ethanol Electro-oxidation | Cyclic Penta-Twinned Rhodium Nanobranches: Isolation, Structural Characterization, and Catalytic Activity |
Choosing a vision model
Vision transformer models seem to have superceded CNNs as cutting edge vision models. Initially (and perhaps still) I thought that fine-tuning a vision transformer such as ViT or Swin would be the way to go. I tried pre-training both of these with masked image modelling (helpful repo here), which uses a partially masked version of original images as training data and the unmasked version as the ground truth. However in the end the vanilla BEiT proved to work better out of the box. A reminder to not reinvent wheels.
Putting it all together
Once the vision and language models are selected, its a simple matter of combining them then training the model via the standard transformers api. (Full writeup in subsequent post)
| |
Training a title-to-abstract model
Section to be completed.
Test the models here
I’ve generated huggingface spaces with gradio apps - they are embedded below if you want to test the models.