For the language-to-language components of this JACS does not exist, I chose Google’s T5 (text-to-text transfer transformer) as a recent cutting-edge text sequence to sequence model.
I had already scraped all the JACS titles and abstracts, so training data was readily available. The first task was to generate somewhat-convincing abstracts from titles to increase the entertainment value of TJDNE.
As abstracts have a maximum length, I wanted to make sure that a whole abstract would be included in T5’s maximum input length of 512 tokens so that end-of-sequence locations could be determined. Here’s a histogram of the length distribution of the abstracts tokenized with the T5 tokenizer.
| |
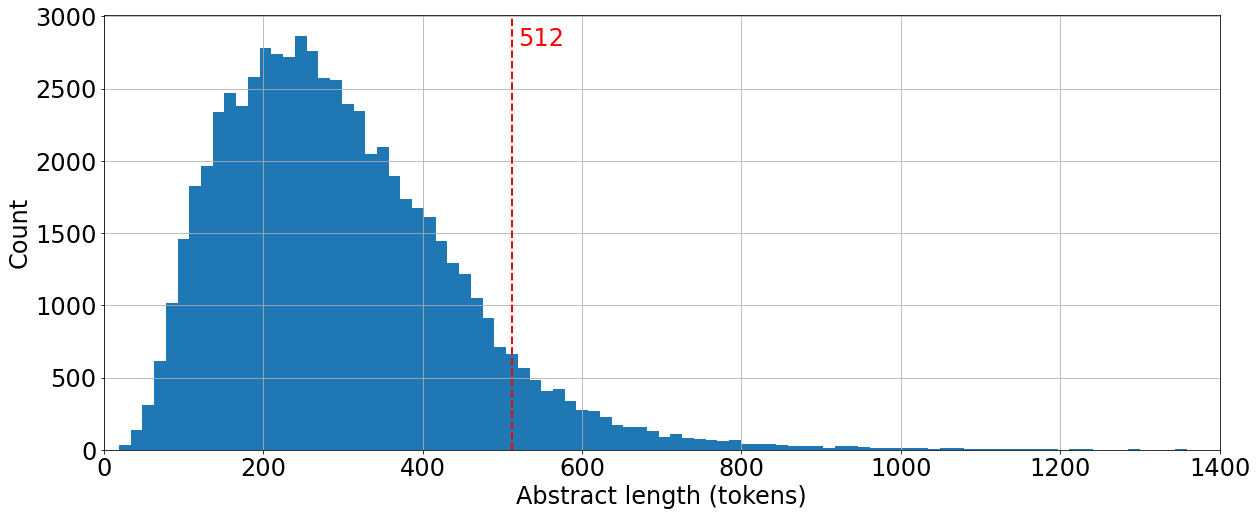
It seems that the vast majority of abstracts are within the 512 token limit, so I didn’t do any further preprocessing. Note - unlike the GPT-2 tokenizer discussed in a previous post, the T5 tokenizer has separate tokens for padding and end-of-sequence, so we don’t need change anything.
To fine-tune the base T5 model, I used a standard Huggingface sequence-to-sequence trainer structure with a pytorch dataset, similar to the one I used for the vision encoder-decoder model discussed in a previous post.
For my previous text generators toc2title a simple model.generate() call was sufficient while title2abstract worked well after adding no_repeat_ngram_size=2.
However, for abstract2title, I wanted to generate multiple distinct but convincing title suggestions from an abstract - essentially a summarization task. After finetuning, the simplest generation methods (greedy and beam search) resulted in very similar suggestions each time. Instead, I used top-K and top-p sampling to generate more distinct and surprising text. This is easily implemented with the top_k and top_p arguments to the generate() method:
| |
If we take the example of my own first paper, you can see that beam search generates very similar results while even with a very limited amount of text, the sampling methods give much more diversity.
| Beam search | Top-K + top-p sampling |
|---|---|
| 1. Negative Thermal Expansion in a Metal–Organic Framework | 1. Negative Thermal Expansion in a Metal–Organic Framework |
| 2. Negative Thermal Expansion in a Metal–Organic Framework Lattice | 2. Dynamics of Metal–Organic Frameworks |
| 3. Negative Thermal Expansion in Metal–Organic Frameworks | 3. Effect of Metal–Organic Framework Contraction on Negative Thermal Expansion |
(Abstract: The action behind contraction: The metal–organic framework [Cu 3 (btc) 2] displays negative thermal expansion (NTE) over a broad temperature range. This property arises from two coincident mechanisms, each of which are unique for NTE systems: the concerted transverse vibration of triangular organic linkers, and the local dynamic distortion of dinuclear metal centers within the framework lattice.)
The real title? Negative Thermal Expansion in the Metal-Organic Framework Material Cu3(1,3,5-benzenetricarboxylate)2